tantin
-
Брой отговори
6627 -
Регистрация
-
Последен вход
-
Days Won
27
Content Type
Профили
Форуми
Библиотека
Articles
Блогове
ВСИЧКО ПУБЛИКУВАНО ОТ tantin
-
Ако ми посочиш поне един по-добре доказан прабългарин - ще черпя. Това погребение с всичките му атрибути е шестица от тотото за прабългарската кауза. Айде, да не е шестица, ама поне за тройка става..
-
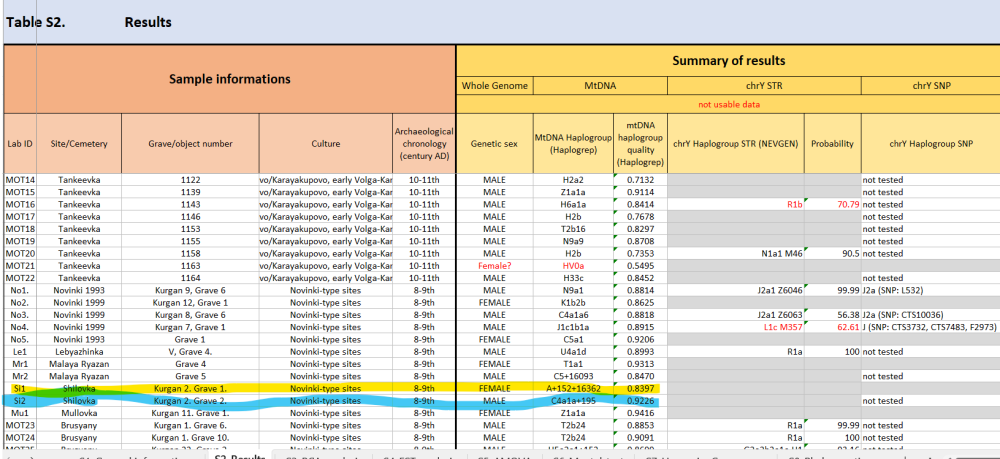
За съжаление точно тоя прабългарин от Шиловския курган, дето най-много ни интересува не е тестван по У хромозома.
-
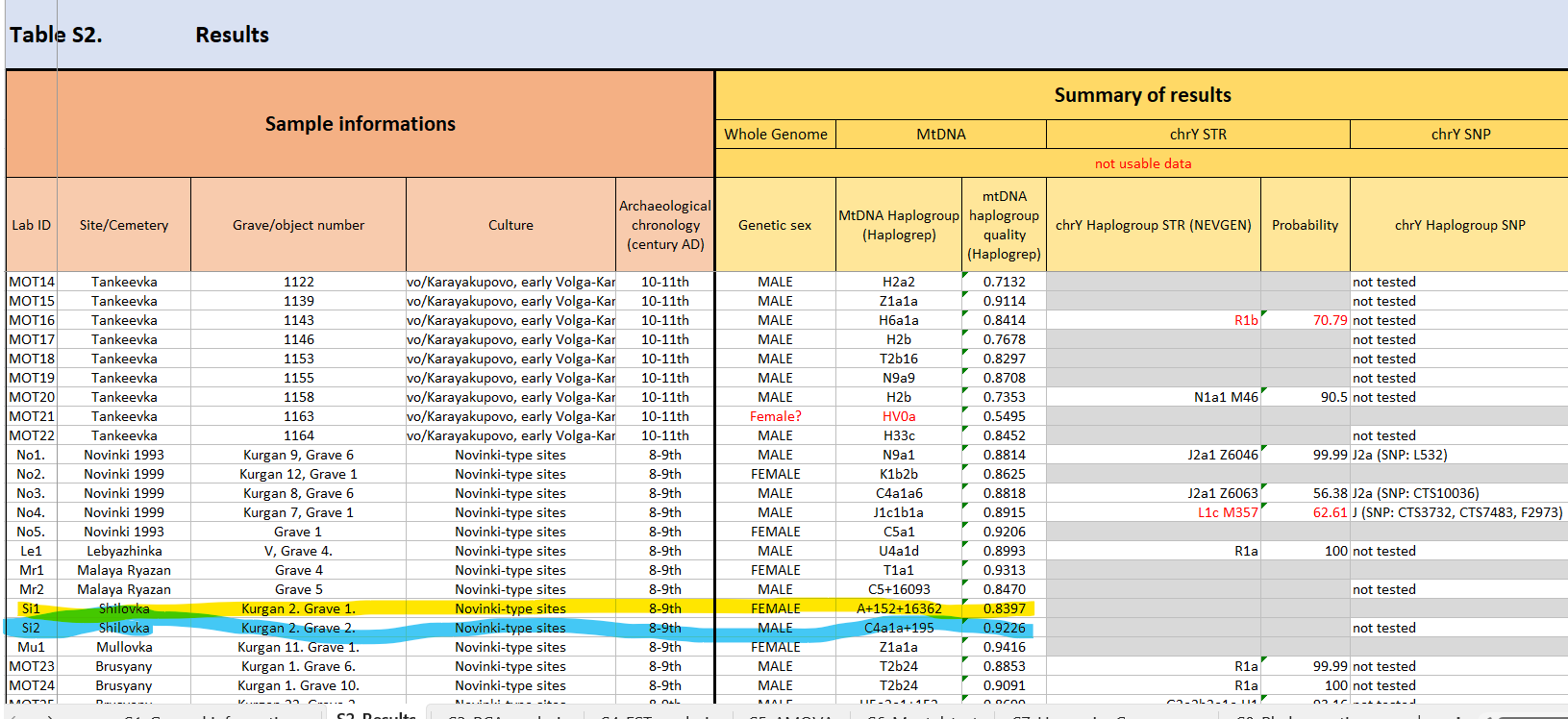
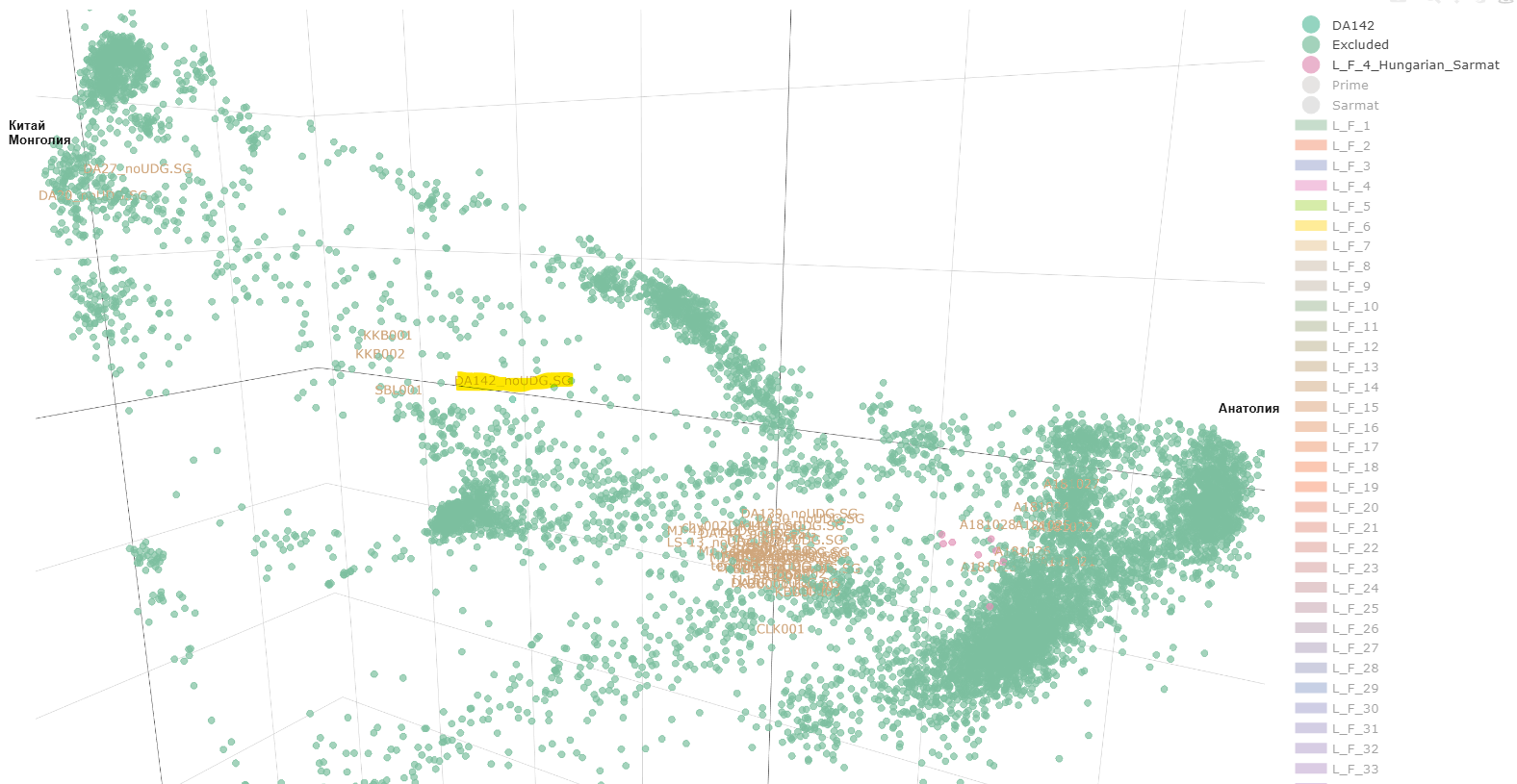
Прабългарски находки от курган - погребение в Шиловка. 5.4. The site at Shilovka In 1992, two kurgans were unearthed during an expedition led by R. S. Bagautdinov from the University of Samara near the village of Shilovka (Sengileyevsky District, Ulyanovsk Oblast). Three graves were discovered under the two kurgans. Even though they had been disturbed, there were the remains of rich furnishing in the tombs: a Byzantine gold solidus and bracteata, earrings with amethyst pendants, a signet ring, bronze and gilded silver elements of a belt set, bone plates decorated with battle and mythological scenes, and a wheel-thrown vessel. The burials were made in the late 7th and early 8th centuries. The ethnicity of the people buried in the kurgan cemetery of Shilovka is still uncertain. The theory of Bulgar and Khazar origins seems currently the most likely (KOMAR 2001). Шиловка Ulyanovsk Oblast Russia 433391 Това е един от сайтовете изследвани от Унгарците: https://doi.org/10.1093/hmg/ddad045

-
Публикация с пълната информация от същия автор. Интересно дали имаме подобни кургани намерени и у нас.
-
Още за курганите с мустаци. Тука се прави опит за историческо обобщение по тези паметници. Доказва се връзка с хуните, става дума също и за прабългарите и аварите.
-
В централен Казахстан са открити над 300 кургани с "мустаци".. Така условно се наричат късни средновековни погребения с оставени около тях каменни насипи, наподобяващи на картинката като дълги мустаци. Почти 200 метра са дълги тези каменни насипи (мустаци). Твърди се че тези кургани с мустаците се появили на територията на Казахстан по времето на Хуните.
-
Виталий Федоров дава тука интересни обосновки за "сарматските" кургани.
-
Ние трябва да кажем мерси че ни отдели време .. (и нерви ). Попътен вятър в новите търсения!
-
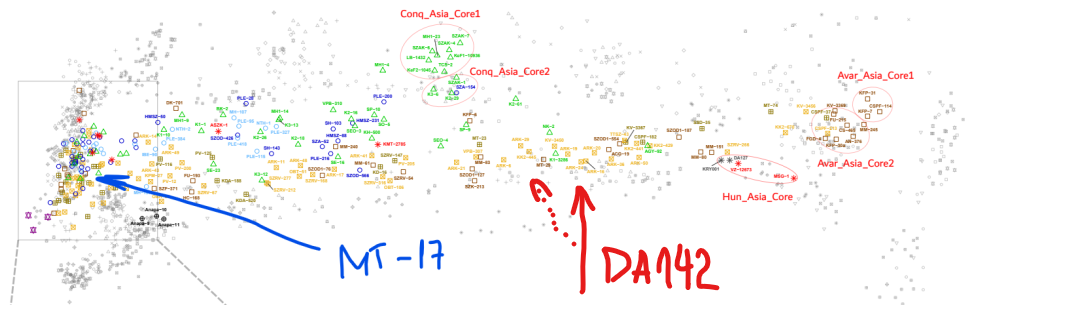
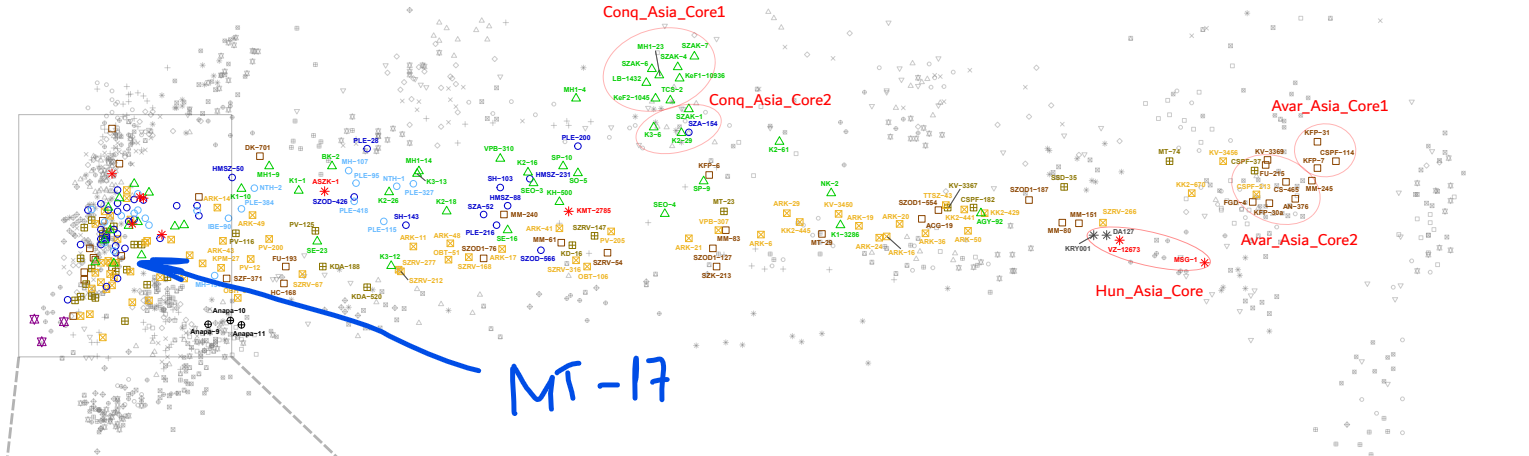
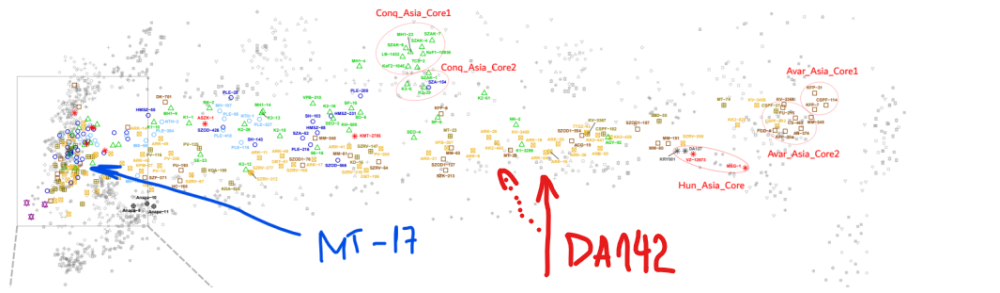
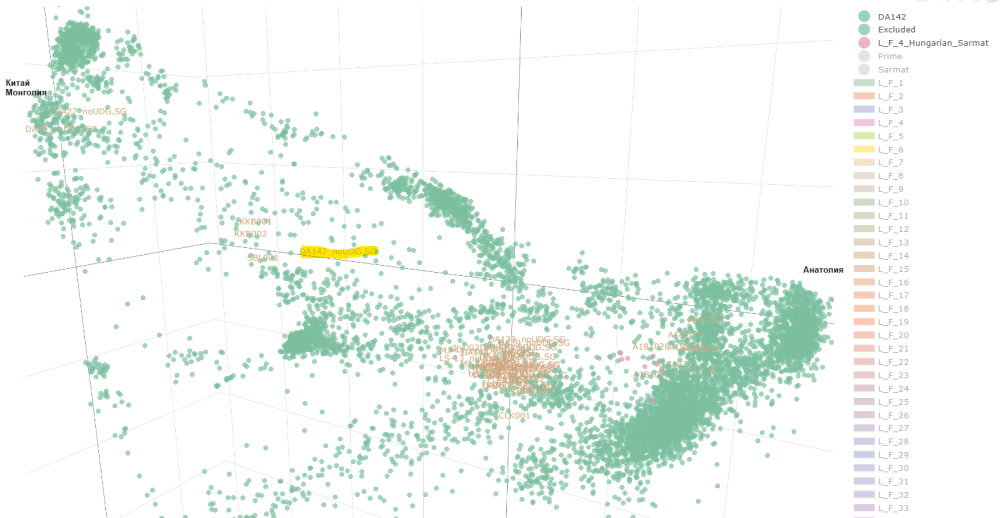
Ако погледнем мястото на DA142 от предишната схема, то можем да предположим приблизително къде трябва да е: Червените линии, ориентировъчно за средата. Дистанцията до източна Азия (генетично) е огромна. Виждаш как всичките европейски проби са наблъскани (нагъчкани) в левия край. Всякакви там тракийци, римляни и ямненци са направо първи братовчеди ако вземем да ги сравняваме с генетичното разнообразие от Азия. И затова DA142 се набутва някъде по средата, нещо като ранен микс на източен азиатец с европейците, 50:50. Но не мога да кажа нищо конкретно, това е на око. Южняка може да пусне адмикс тоолс и да го види по компоненти. А тези другите унгарски ( с МТ-17) ги има на публикация, но генетичните данни май бяха само в суров вид. Тоест нямаме ги във формат плинк. Предполага се че те в общи линии повтарят другите унгарски(аварски) дето ги имаме достъпни.
-
Този войн MT-17 , заровен с аварите си е почти чист европеец. The Middle Avar MT-17 individual from Madaras-Téglavető in the Eur-cline also carried R1a-Z94, although in this cemetery, all three other males carried N1a1a1a1a3a with Asian genomes.

-
Не става ясно за коя точно проба . Най-вероятно е от това изследване: DOI: 10.1016/j.cub.2022.04.093 Кода на пробата е: MT-17 https://www.ebi.ac.uk/ena/browser/view/ERS9945166
-
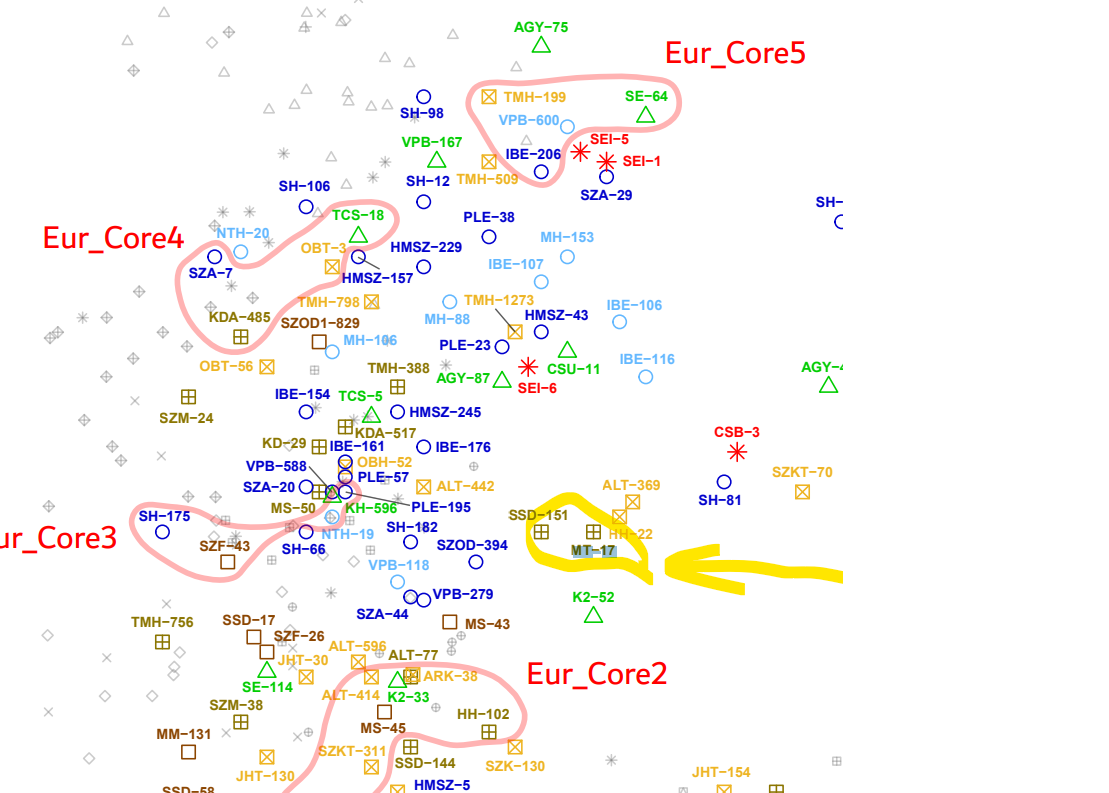
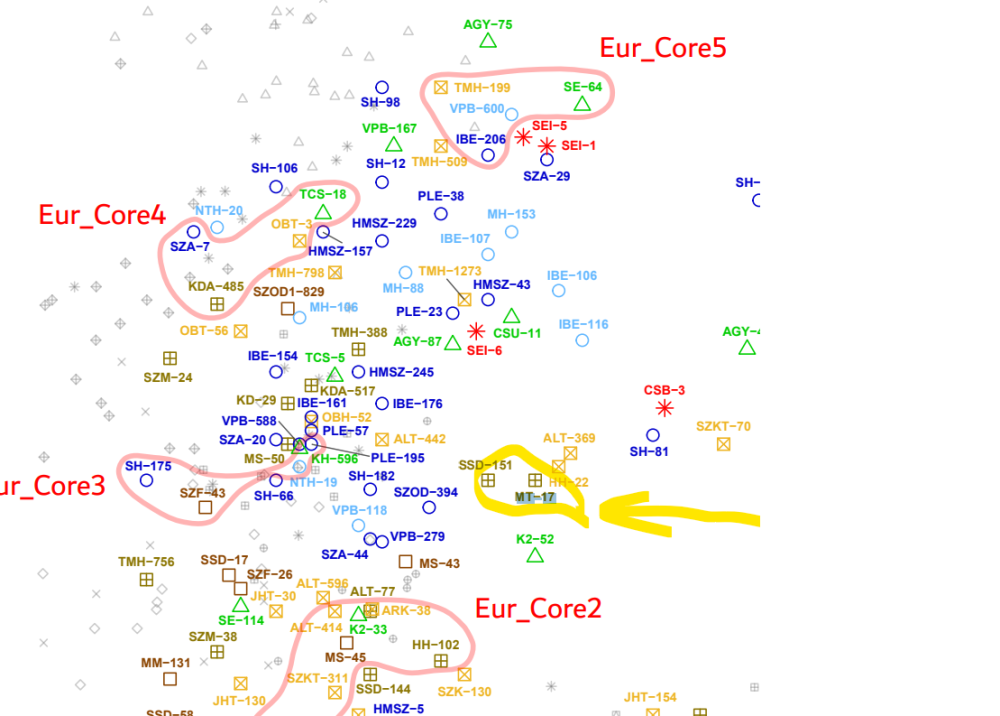
Много добре ги е показал Атома с тая извадка от Г25. И приблизително така са разпръснати, така са се омешали с близки и далечни групи. В тая извадка са проби от Монголия. А подобни извадки с разпръснати индивиди имаме и от Унгария, също подобниимаме и от Казахстан. Първо по времето на Скития-Сарматия после с хуни , тюрки и авари картината не се променя кой знае колко. Някаква нова група завзема политическата власт, но териториите на бившите скити са приблизително същите, в някогашните скитски пространства на огромни разтояния има бързи смени на политическата власт, съответно конни отряди се придвижват и налагат политическата власт над някакви части от Европейско-азиатската степ. Можем ли да правим някакви езикови предвиждания? Можем разбира се. Хората с типично изтоно-азиатски гени най-вероятно ще да са говорили езици от типа на тунгуско-манджурски, турски и монголски. Хората откъм европейската част е по-вероятно да са говорили индо-европейски езици свързани с ирански, тохарски а ако щете и латински. Фино-угрите също може да са участвали в тоя езикови обмен. Особено с примера с унгарците. Намирането на дадена група и позиционирането им на картата на гените ни дава доста информация и за тяхното формиране. Многото проби от Унгария, Монголия, Казахстан, Русия вече ни помогнаха да видим как е изглеждало населението на степите. Обаче липсата на достатъчен брой проби от средновековна България не ни позволява да преценим как точно се е стигнало до окончателното формиране на съвременното балканско население. И още нещо интересно: погребенията на царе, елитни войни и шамани в много случаи ни показват гени различни от това на масовото население. За да можем да правим надеждни изводи ни трябват по-голям брой проби, което пък е скъпа процедура и само държавите с повечко петрол и доходи или външна субсидия могат да го правят системно. Проблема с българските проблеми донякъде е в липсата на национална политика, в липсата на консенсус. Археолози много, и кости има изровени премного, но не мога да го разбера как така няма единна политика, а хора като Чобанов трябва да ходят тука и там и да искат от тоя и оня. При условие че си има министерства и един куп народ в Бг си изкарва хляба с парите и събсидийте от бюджета. Тоест поддържа се огромна мрежа от музеи, археолози.. Има закони за културно-историческото наследство. А като стане въпрос за тия новите изследвания няма човек на официална държавна дейност дето да координира усилия, работа и пари.. Някакви доброволци шетат насам натам, а държавата я няма. За да има "дейност" трябва да има фондове и отчетност. Отдавна към културното министерство и към министерство на здравето е трябвало да се създадат такива направления, обаче явно се чака дядо сорос да отвори поредния чувал и да тръгне да раздава коледни подараъци.
-
Хуно-сарматски курган в Казахстан
-
Напротив, сега с новите генетични изследвания точно старата 150 годишна става най-актуалната. На фона на всичките нови "извращенци" старата теза придоби нов смисъл и трябва да бъде отстоявана, за да не се вкарват младите в грешки и заблуди. ПП. "Извращавам" идва от въртя, завъртам. Етимологията на тая тема идва от завъртам, обръщам. Отклонявам от пътя. Тоя термин се ползва много в ранното християнство, свързан с вярванията. Четох някакъв старослявянски текст скоро и там тая думичка се срещаше. Точно новите теории може да бъдат наречени "извращенски".. Въпросите и борбата винаги са били за истината. Когато едно нещо се докаже за истина, всичко останало се превръща в "извращенство". Но абсолютната истина е трудно-достижима. Трябва да подхождаме по-философски и да не залитаме в абсолютизъм. (нека сме повече демократи).
-
И най-важното - публикувай календара, защото съм се обзаложил на половинка ракия за него Аз ли да го публикувам или Макето ?
-
Ако имаш много сериозни научни доказателства и ако си на път да създадеш нова и аргументирана теория - то твоя задача и отговорност е да създадеш нови и необременени понятия. Така се прави в науката. Въвеждаш някакво ново понятие, нови етапи, нови разграничителни линии и продължаваш. Но понеже ти нямаш нищо, то естествено няма да ги създадеш тия нови понятия и нови разграничителни линии. Тогава от какъв зор скачаш на старите и утвърдени термини ? Хем ви се ще да сътворите нещо ново, хем не можете да мръднете от мястото.. Не може да подскочите. За да докажеш че прабългарската теория била грешна -> докажи го, публикувай си иранската хипотеза, вкарай в употреба пра-иранизмите или там както ти решиш да ги наречеш, докажи всякакви там скитски и сарматски тези и продължавай напред. Но естествено не можеш, щото като тръгнеш да го правиш най-вероянто ще станеш за смях като траколозите..
-
Всички основни народи по света си имат пра-родители, пра- население от което са тръгнали, първо-източник. Давам примери: славяни - прото-славяни германци - прото-германци англичани - при тях прото-населението дало наименованието са англитеа(германско племе), затова техните пра-родители са от групата на прото-германците келти -? траки - вероятното прото- население са ямна И така нататъка. Не е нужно непременно в термина да се включва представката за прото-. Това си е част от словообразуването и си има предостатъчно изключения. Прабългарите като термин е въведено в употреба от времето когато е започнало създаването на новия и модерен български език. И затова тоя термин се е наложил в началната му книжовна форма. В съвременната употреба се ползва еднакво и прото-българи.
-
Кое е това дето ти наричаш извращение? Май ти не си нещо наясно с терминология въведена отпреди 150 години. Прабългарите като понятие е въведено още отпреди да я има новата ни 3-та българска държава. А за българите се е говорело още отпреди да я има Първата Българска Държава. По-леко и премерено с понятията, тука сме уж научен форум, а ти си ползваш понятия от махалата.
-
Ако тръгнем надълбоко с легендите и хипотезите можем да изкараме Крал Артур и рицарите на кръглата маса за алани или хуни. И какво от това? От това англичаните няма да станат ни алани, ни хуни. Англичаните си имат достатъчно германска, римска, келтска, нормандска... И други жилки. Дори и тракийски следи се откриват на острова. Щото по римско време в римската армия било пълно с тракийци. Легендите са си част от произхода. А народонаселението може да е съвсем различно от легендарния създател на държавата. И това важи за къде ли не: руснаци-варяги Римляни-Ромул и Рем Англичани- принц Артур французи - германеца Франк Велики .... И още и още.. Напъните да се докаже че българския народ носи непременно гените на легендарния Авитохол и хуните са изначало погрешни. Легендарния основател и рицарите на кръглата маса (хранениците) са добре документирани у нас. За да се стане храненик не е било нужно да докажеш гените си и произхода си. Храненик (рицар) се е ставало с меч и геройство, с проливане на чужда кръв, с вярност към владетеля ... С много смелост. Това е поуката от всички легенди. И вероятно така е било.
-
На база генетика няма как да се докаже дали тоя тяншански хун е свързан с прабългарите. Но ако имаме 50-100 генома от него време от Плиска и околностите, то може на база IBD да се търси роднинска връзка с други хуни и централно-азиатци и тогава ще стане ясно има ли такива връзки. Иначе оставяме на археолозите да сравняват керамика и гробни инвентари. Но генетиката е много по-мощна като експертиза. Ако се открие близка родственост генетиката може да каже какъв е вида родство , примерно 5-ти братовчеди. Или някакви наследници. База за сравняване има, само нямаме наши проби за да сравняваме.
-
А това са първите 10 най-близки до DA142 [1] "DA142_noUDG.SG" "DA385_noUDG.SG" "DA96_noUDG.SG" "DA71_noUDG.SG" "DA100_noUDG.SG" [6] "DA52_noUDG.SG" "Turkmens1.SG" "DA74_noUDG.SG" "DA222_noUDG.SG" "Turkmens2.SG"
-
ТянШан нали беше планината Имеон ?
-
Предишната информация беше на око. Проверих го по-точно: Kyrgyzstan_TianShan_Hun.SG 5742 Kyrgyzstan_TianShan_Hun.SG DA385_noUDG.SG Това е най-близкия.
-
Понеже много го коментирате ДА142, показвам и него. Типичен средна Азия. Може да се каже че е на същата аварска линия. Най-близо до него са 2 киргизи, 1 Сака и един от Xiongnu.
-
https://ru.wikipedia.org/wiki/Булгары#cite_note-10